Mysql 取最早时间出现的数据
场景:有若干客户购买记录,统计出现的新客户(即客户第一次出现的时间)。
思路是根据名称分组,然后取分组中最早时间出现的数据。
话不多说,实验如下:
创建测试表
CREATE TABLE test_table(
`id` INT UNSIGNED AUTO_INCREMENT,
`create_time` DATE ,
`name` VARCHAR(15) NOT NULL,
PRIMARY KEY ( `id` )
) ENGINE=INNODB DEFAULT CHARSET=utf8;
插入测试数据
INSERT INTO `test_table` (`id`, `create_time`, `name`) VALUES('1','2022-12-07','张三');
INSERT INTO `test_table` (`id`, `create_time`, `name`) VALUES('2','2022-12-06','张三');
INSERT INTO `test_table` (`id`, `create_time`, `name`) VALUES('3','2022-12-05','李四');
INSERT INTO `test_table` (`id`, `create_time`, `name`) VALUES('4','2022-11-02','王五');
INSERT INTO `test_table` (`id`, `create_time`, `name`) VALUES('5','2022-09-28','赵六');
INSERT INTO `test_table` (`id`, `create_time`, `name`) VALUES('6','2022-08-02','赵六');
表数据如下:
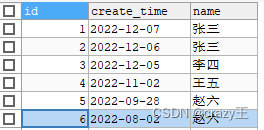
可以看到,张三和赵六分别出现了两次,各自最早出现的时间应该取id=2和id=6的数据。预期结果应该是id为2、3、4、6的数据。
实现sql:
SELECT
a.id,
a.name,
a.create_time
FROM
test_table AS a
INNER JOIN (
SELECT
SUBSTRING_INDEX(
GROUP_CONCAT(id ORDER BY create_time),
',',
1
) AS id
FROM
test_table
GROUP BY
`name`
) b ON a.id = b.id;
查询结果如下,与预期相同:

SQL分析
其中最主要的就是 GROUP_CONCAT() 函数将组中的字符串连接成为具有各种选项的单个字符串。
语法:
GROUP_CONCAT(DISTINCT expression
ORDER BY expression
SEPARATOR sep);
看下通过名称分组,根据时间排序后此函数效果
SELECT GROUP_CONCAT(id ORDER BY create_time )AS group_id_text FROM test_table GROUP BY `name`;
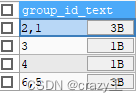
效果如上图,然后通过*SUBSTRING_INDEX()*函数取第一位,即是此名称最早出现的数据id。
SELECT SUBSTRING_INDEX( GROUP_CONCAT( id ORDER BY create_time ), ',', 1 ) AS id FROM test_table GROUP BY `name`;
最后内关联查询完整数据:
SELECT
a.id,
a.name,
a.create_time
FROM
test_table AS a
INNER JOIN (
SELECT
SUBSTRING_INDEX(
GROUP_CONCAT(id ORDER BY create_time),
',',
1
) AS id
FROM
test_table
GROUP BY
`name`
) b ON a.id = b.id;
结束
本图文内容来源于网友网络收集整理提供,作为学习参考使用,版权属于原作者。
THE END
二维码